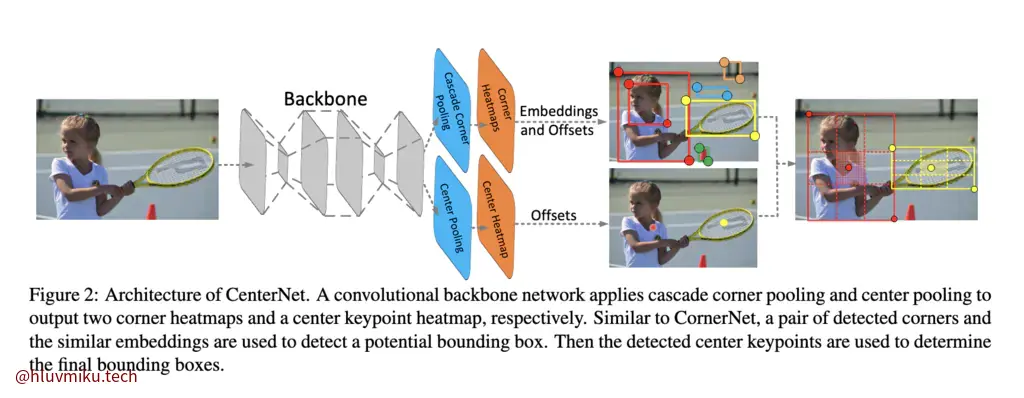
最近在想Key-point Detection的事,GPT说这个很经典,遂读。但好像不是我想的那种Key-point Detection。作者还是ICT的。
简单来说,这篇文章在CornerNet的基础上利用双分支,一路预测角点,一路预测中心点,并认为中心点应该位于bbox的中心区域。文章认为:
since each object is constructed by a pair of corners, the algorithm is sensitive to detect the boundary of objects, meanwhile not being aware of which pairs of keypoints should be grouped into objects.
也就是说,CornerNet只关注边界在哪,而忽视了哪些pair是一个目标对应的pair。为了解决这个问题,文章提出了CenterNet,并在架构上做了如下两个设计:
- center pooling: 对feature map在X、Y上分别取最大,找到最大元素,取交点作为center point
- cascade corner pooling: 不仅在boundary找关键点,还在内部找
3. Our Approach
接下来我们看看它的具体实现。
Object Detection as Keypoint Triplets
为解决“哪些pair属于同一个object”的问题,文章使用了如下算法:
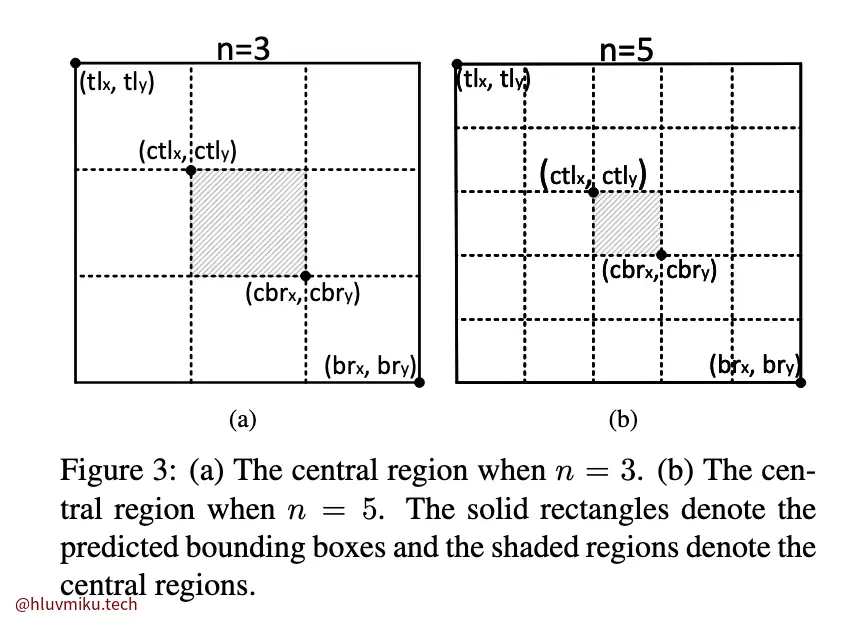
(1) select top-k center keypoints according to their scores; (2) use the corresponding offsets to remap these center keypoints to the input image; (3) define a central region for each bounding box and check if the central region contains center keypoints. Note that the class labels of the checked center keypoints should be same as that of the bounding box; (4) if a center keypoint is detected in the central region, we will preserve the bounding box.
简要来说,模型独立预测corner points与center points,然后选择那些**“能让center points落在bbox中心的那些bbox”**。这是文章的核心思路。
Enriching Center and Corner Information
接下来让我们看看在模块设计上文章怎么做的。
Center pooling.
The backbone outputs a feature map, and to determine if a pixel in the feature map is a center keypoint, we need to find the maximum value in its both horizontal and vertical directions and add them together. By doing this, center pooling helps the better detection of center keypoints.
就如我开头所说,对feature map在X、Y上分别取最大,找到最大元素,取交点作为center point。注意这里的取最大不是什么L1、L2、余弦相似度啥的,就是纯粹的数值最大值。
Cascade corner pooling.
It first looks along a boundary to find a boundary maximum value, then looks inside along the location of the boundary maximum value to find an internal maximum value, and finally, add the two maximum values together. By doing this, the corners obtain both the the boundary information and the visual patterns of objects.

简单来说,他就是pool了以后再把另一个方向也给加进来再pool:
def forward(self, x): # pool 1 look_conv1 = self.look_conv1(x) p1_conv1 = self.p1_conv1(x) look_right = self.pool2(look_conv1) P1_look_conv = self.P1_look_conv(p1_conv1+look_right) pool1 = self.pool1(P1_look_conv)
# pool 2 look_conv2 = self.look_conv2(x) p2_conv1 = self.p2_conv1(x) look_down = self.pool1(look_conv2) P2_look_conv = self.P2_look_conv(p2_conv1+look_down) pool2 = self.pool2(P2_look_conv)
# pool 1 + pool 2 p_conv1 = self.p_conv1(pool1 + pool2) p_bn1 = self.p_bn1(p_conv1)
conv1 = self.conv1(x) bn1 = self.bn1(conv1) relu1 = self.relu1(p_bn1 + bn1)
conv2 = self.conv2(relu1) return conv2总结
挺有趣的工作,但是引入了很主观的先验,据说对旋转目标效果不好。