-
【日报】2026-03-31 上午看了看论文,下午和师兄讨论了会然后干横向。晚上干横向。 横向原始方案是yolo,我也打算用yolo了,原来的纯cv方案就留几张图做纪念吧。 image.png yolo效果太好了。
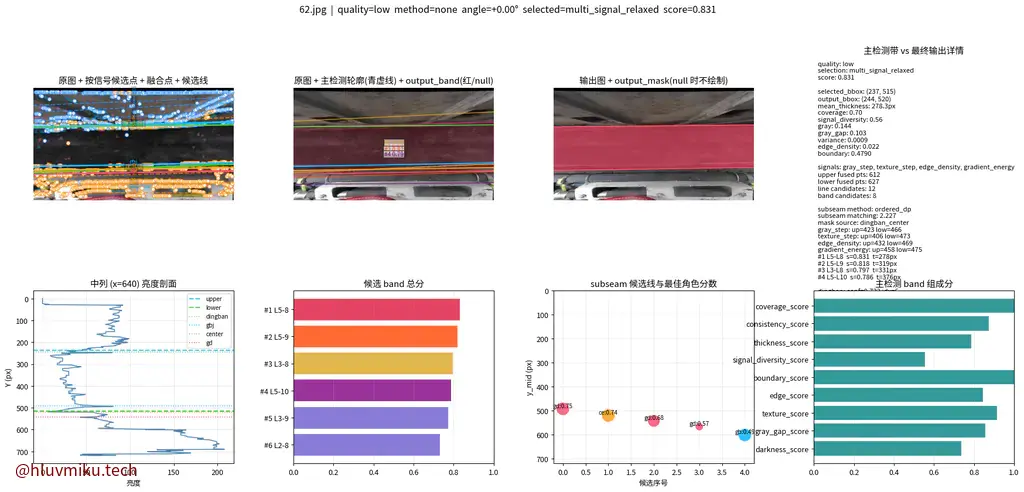 2026年3月31日
2026年3月31日 -
【日报】2026-03-30
2026年3月30日 -
【日报】2026-03-26 一天课。让Claude+我的一些思路写了下横向。传统CV方法,单图50ms,看着还不错。 image.png 当然也有差的: image.png 和师兄线上讨论了下。
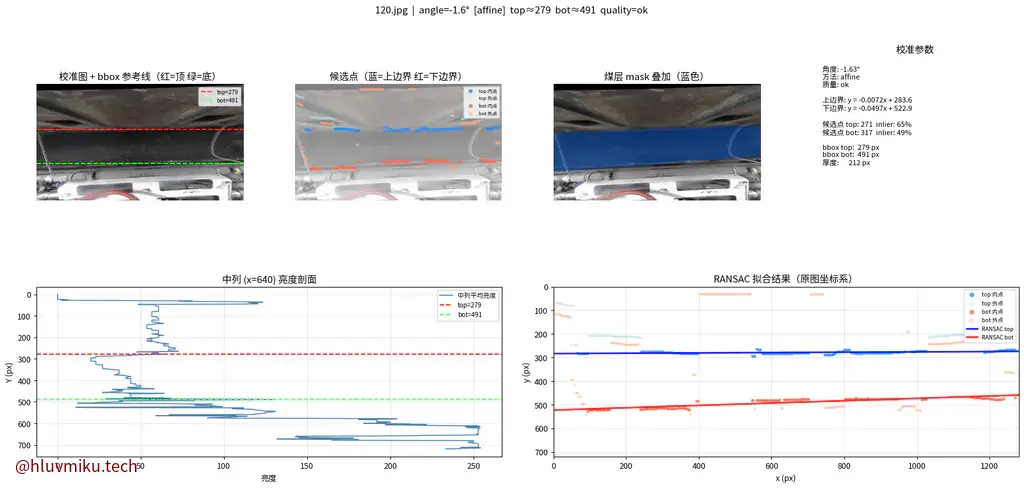
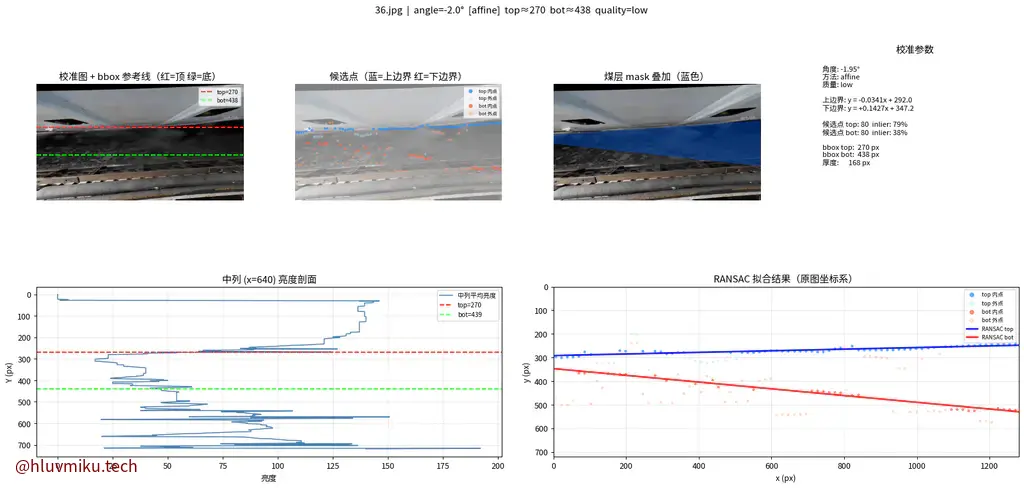 2026年3月26日
2026年3月26日 -
【日报】2026-03-25 上课。
2026年3月25日 -
【日报】2026-03-24 嗓子哑了。上午讲了一小时,下午先和张蔚师兄交流了两小时,又和代老师说了一小时,又和张蔚师兄说了会,然后又找鑫源师兄聊了会。吃完饭又和同门聊了一阵。啥事没干,手头又多了一堆论文没看。 互通有无固然是好事,但还是会牺牲知识传授方大量时间和精力。
2026年3月24日