-
【日报】2026-06-01 服务器出问题了。消融实验还在跑。这几天横向是做不了了。 终于有空折腾全景了,攒了十多篇论文没看。 感觉在横向上投入精力有点太多了。我想之后我就蒸馏+微调个输入小点的模型就差不多了。
2026年6月1日 -
【日报】2026-05-29 这几天主要做横向,搭了个测试环境、采集数据、明确需求、训练模型、切换技术方案、蒸馏啥的,干了一堆活,都不知道怎么总结,做的太多了。还有一堆探索过的技术路线废案更是不知如何呈现。 全景数据还在爬,也还在帮师兄推进消融实验。
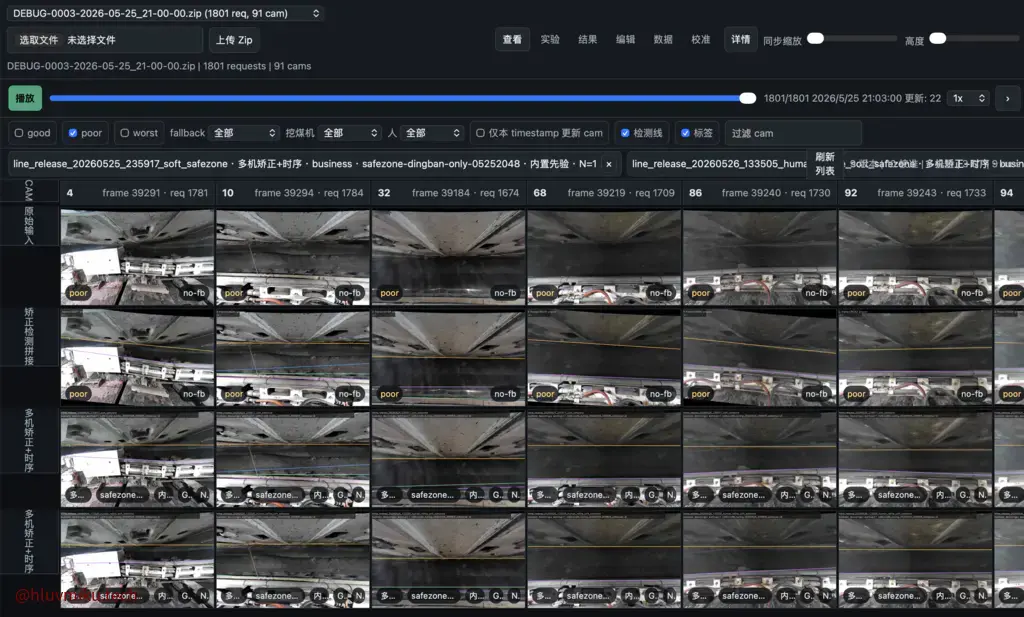
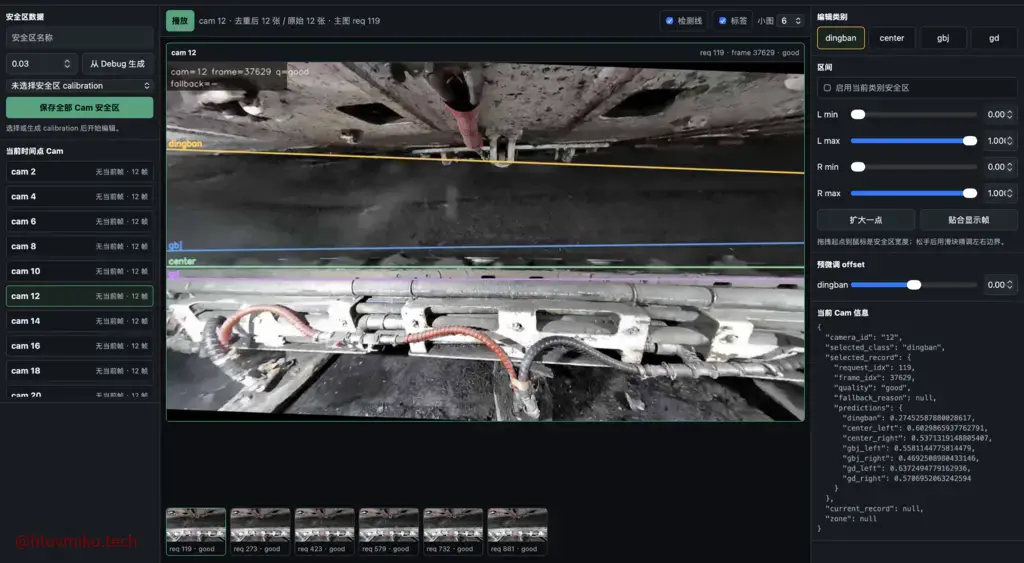 2026年5月29日
2026年5月29日 -
【日报】2026-05-19 开了一天会。 明天把消融实验脚本打通、爬虫代码确认,后天给横向新的predict函数+文档、完成大规模标注数据管线,周五/下周一分发代校对数据,全景相关的还有好多paper想看没时间。 事好多。
2026年5月19日 -
【日报】2026-05-18 这周越野跑太累了,导致周末没更新横向。 今天横向predict函数重新写了个,师兄的LabelFlow我重构好了没大问题,自己想下的数据集下载脚本准备好了,打算回校后下载,然后拷服务器里(太大了) 事情不少。
2026年5月18日 -
【日报】2026-05-14 换了台Ubuntu系统电脑后日报写的少了很多,因为notion没有Ubuntu客户端,得用网页版。
2026年5月14日