-
【日报】2026-06-16 横向感觉检测部分能做的基本都做的差不多了。
2026年6月16日 -
【日报】2026-06-11 最近全景越思考越感觉不知道做啥好。 能做的东西有很多,做了真正有用的却很少——整个全景领域应用场景都很尴尬。 毕竟Insta、Meta、Apple Vision Pro都没能撑起全景方向。 平面图像>单鱼眼镜头>双鱼眼镜头>全景。 应用场景有哪些?VR、全景视频、全景无人机、全景监控。 最近看阿里几个员工写的长文,提到做产品要讲究“发心”。“发心”,放到科研领域就是motivation,不是某篇Paper的Motavation,是“做“这篇paper的motivation。想发A会、想毕业、希望改善某项技术、”我觉得这里或许能这样做“,这些都是科研的”发心“。 但我感觉在全景领域我缺少一个所谓的”发心“。自然语言处理、平面CV、自动控制,他们都有各自宏大的终极目标,全景领域呢?起码对我来说,最大的目标是赶上平面CV。深入挖掘下去,我发现全景领域在做的无非是:“全景拆成平面可能要切成20个平面跑20轮平面模型,我在全景上只要1轮。” 但是到底哪里有需要整个球面场景都被需要的场合呢?我仔细研究了下insta、VR,发现即使是 这些场景里,有用的也都只是一个小区域,那也就都可以等价为一个切平面。这次横向倒还是有点意思,用普通的相机覆盖不全场景,需要鱼眼相机。但这也不是全景,而且处理起来还是用的平面的技术,加上个校畸。但似乎也就局限于此了。 做个大规模的数据集,我感觉能做下去对全景方向还是挺有意义的。但是全景方向的意义,我还没想明白。或许具身智能、世界模型又需要全景吧?毕竟对人来说,消费的往往只是一个小平面,对机器人、世界模型来说就不一样了。
2026年6月11日 -
【日报】2026-06-09 今天公众号刷到一篇cvpr 我一看,这去年我研究点监督的时候也考虑过这样用DINOv3。这篇文章主要解决了DINOv3存在位置bias的问题,他的做法是提取出这个bias然后投影到正交补空间上,我当时的是认为这些是2D RoPE特性导致的,然后直接去除了RoPE编码。去年的组会PPT。 当时做的是点监督,那时候也在想,如果能拿到一个物体的mask我估计就能很方便的出mask了,但是没往那方向做。 看来选对Task很重要。此外,之前我整体实现思路也远不如它,导致我最终分割效果非常差。
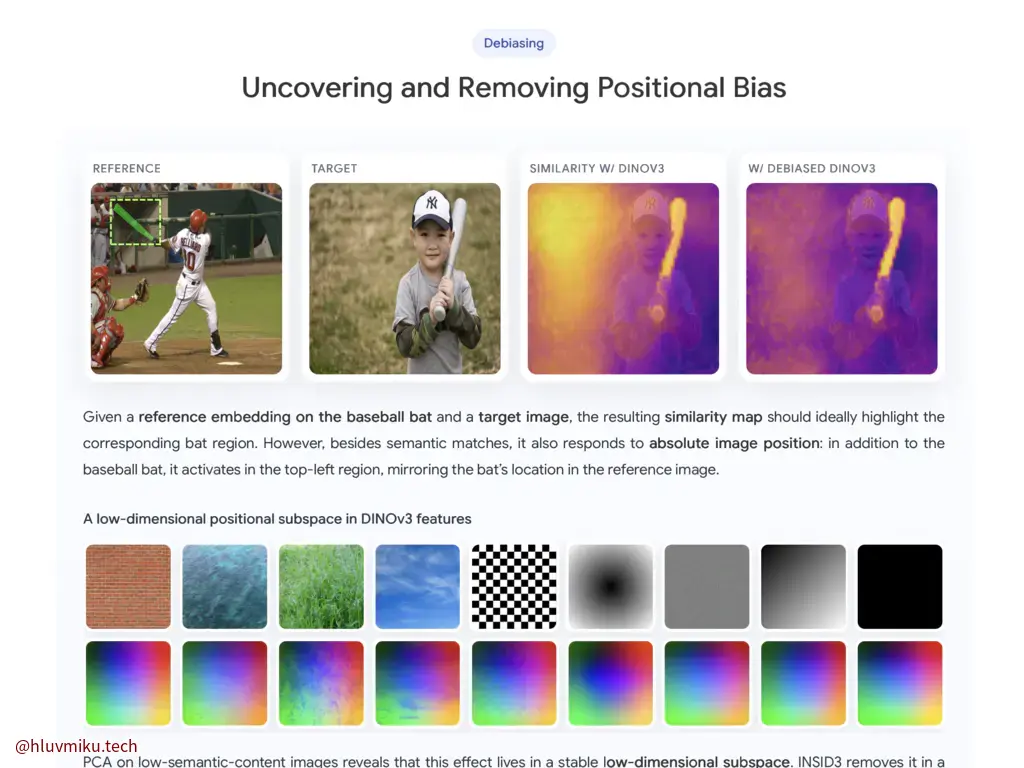
 2026年6月9日
2026年6月9日 -
【日报】2026-06-05 明天考一门,周四考两门,下周日考一门。 今天解决了全景数据集解析问题。
2026年6月5日 -
【日报】2026-06-02 在研究auto-research。 这几天要开始复习了,也不是太有时间干活。
2026年6月2日