概览
SAM2提出了**PVS(Promptable Visual Segmentation)**任务。在 Section 3 与 Appendix B 中,文章给出了他的具体定义。在 Section 3 中,文章具体描述了这个任务为:
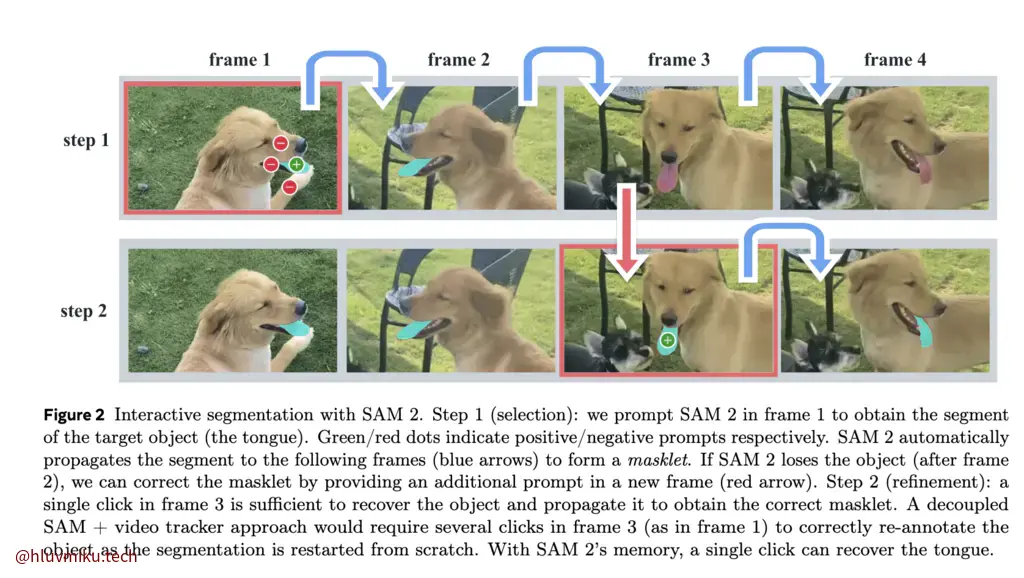
Our PVS task allows providing prompts to the model on any frame of a video. Prompts can be positive/negative clicks, boxes, or masks, either to define an object to segment or to refine a model-predicted one. To provide an interactive experience, upon receiving a prompt on a specific frame, the model should immediately respond with a valid segmentation mask of the object on this frame. After receiving initial prompts (either on the same frame or different frames), the model should propagate these prompts to obtain the masklet of the object across the entire video, localizing the segmentation mask of the target on every video frame. Additional prompts can be provided to the model on any frame to refine the segment throughout the video (example in Fig. 2).
简要来讲,他将Segment Anything的Task在 “视频与交互” 的领域做了延伸扩展。文章着重点出了 propagate 这一概念。具体来说,这意味着模型应该将帧间稀疏的标注传递到每一帧。
相较SAM,SAM2更聚焦于视频中物体的连续分割。在SAM2的实现中,它设计了一个Memory Bank与Memory Attention用以保留并 propagate 帧间的Mask结果与prompt。
与SAM类似,它也采用了和SAM一致的Image Encoder、一致的Prompt Encoder与结构类似的Mask Decoder。在工作进行过程中,SAM2也着重聚焦于Data Engine的构建——本质上,他也是一个数据工程。
我认为贡献如下:
- 定义了PVS这一任务
- 设计了Memory Bank与Memory Attention的架构用于帧间prompts传递与帧间分割一致性
- 设计了渐进式数据引擎
- 发布了SA-V数据集
Related Work
- Image segmentation:在本文中主要聚焦于SAM以及SAM的下游工作。
- Interactive Video Object Segmentation (iVOS):对于视频,可交互的标注希望连续追踪的目标物体,模型及时的响应、分割。
- Video Object Segmentation (VOS):对于视频,在第一帧标注出目标物体,模型应该自动在整个视频中标注出目标。
- Video segmentation datasets:常见的VOS数据集如:Yotube-VOS、DAVIS
Task: promptable visual segmentation
对PVS的具体定义如下:
Our PVS task allows providing prompts to the model on any frame of a video. Prompts can be positive/negative clicks, boxes, or masks, either to define an object to segment or to refine a model-predicted one. To provide an interactive experience, upon receiving a prompt on a specific frame, the model should immediately respond with a valid segmentation mask of the object on this frame. After receiving initial prompts (either on the same frame or different frames), the model should propagate these prompts to obtain the masklet of the object across the entire video, localizing the segmentation mask of the target on every video frame. Additional prompts can be provided to the model on any frame to refine the segment throughout the video (example in Fig. 2).
Model & Appendix D
模型架构非常值得一读。简要来说,他在SAM的基础上,增加了Memory Bank与Memory Attention,用以实现在视频帧间进行propagate。架构如下:
- Image encoder
- Memory attention
- Prompt encoder and mask decoder
- Memory encoder
- Memory bank
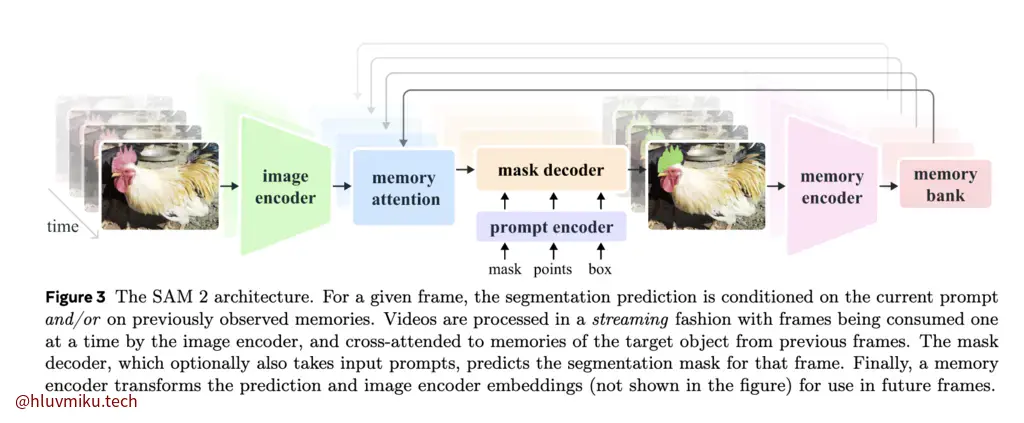
相较SAM,SAM2多了很多Memory的架构。
在这一章中有提到:
The frame embedding used by the SAM 2 decoder is not directly from an image encoder and is instead conditioned on memories of past predictions and prompted frames. It is possible for prompted frames to also come “from the future” relative to the current frame. Memories of frames are created by the memory encoder based on the current prediction and placed in a memory bank for use in subsequent frames. The memory attention operation takes the per-frame embedding from the image encoder and conditions it on the memory bank, before the mask decoder ingests it to form a prediction.
这里说到”prompted frames to also come “from the future” relative to the current frame”。我对其理解是这样的:Memory Bank保存分两部分(见下文)——过去预测帧与提示帧。在其中,过去预测帧都是 “from past” 的,而提示帧则可能来自当前图片后面。我想我之后需要深度挖掘一下代码来确定下。
Image Encoder
SAM2的Image Encoder采用了Hiera Image Encoder。Hiera Image Encoder是Meta提出的一个高性能Image Encoder,它主张通过强大的预训练任务(如 MAE)来替代分层视觉 Transformer 中专用模块(例如卷积)提供的空间偏差。
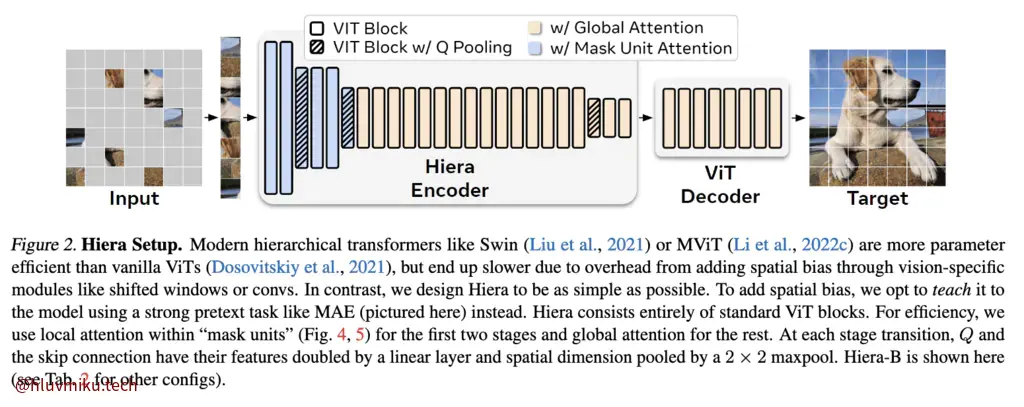
这是什么意思呢?原始的的ViT也没有“专用模块”啊?确实,原始的的ViT没有。
但是”分层视觉 Transformer”比如大名鼎鼎的Swin Transformer就有:
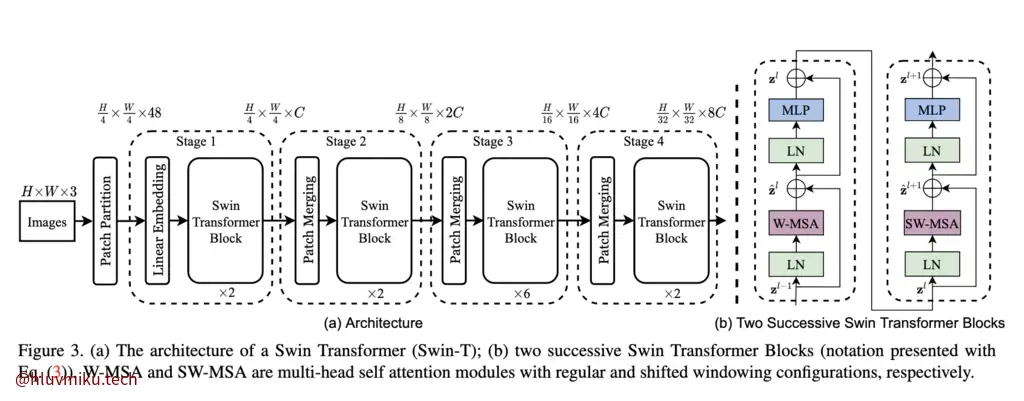
好,Hiera 确实没有繁杂的Patch merging操作,但是他却有“Q Pooling”,这又是什么?下图是MViT给出的Q Pooling/Pooling attention架构:
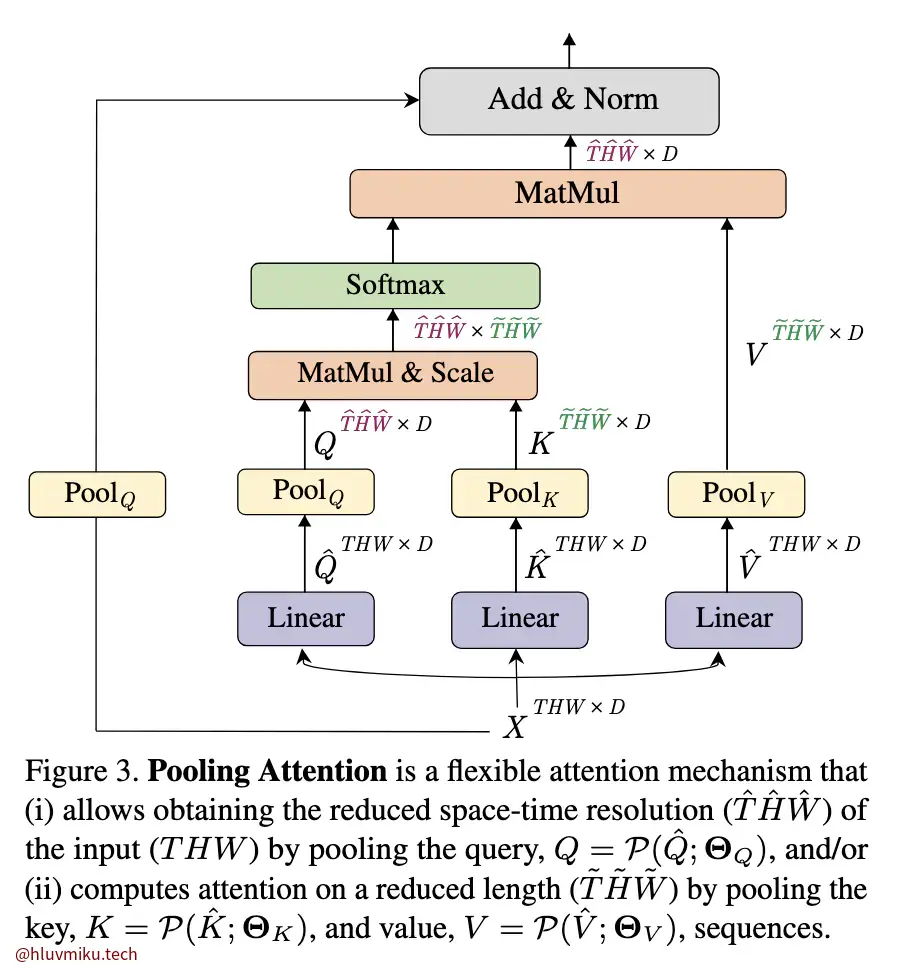
简单来说,原始的Attention是:
而Pooling Attention对KV的输入都进行了Pooling:
仔细看维度会发现,如果只是为了降维,只需对Q进行Pooling就行了,此外需要保证KV的第一维保持一致。 Untitled 中,他们通过实验发现对KV也进行Pooling比较有效,就也分别加上了。
回到SAM2的Hiera,我们其实还有一个问题没解决。文中提到:
We follow Bolya et al. (2023) in using windowed absolute positional embeddings in the Hiera image encoder.
简要来说,Bolya et al. (2023) 的文章 Untitled 发现,”If we take an original Hiera-L model pretrained on 224px images and finetune it on 256px images for ImageNet-1k (Deng et al., 2009), the top-1 accuracy drops by 0.4% (see “absolute” in Tab. 1).”这与输入图像越大,精度应该越高的已知结论正好相反。论文在深入研究以后发现这是由于模型代码对相对位置编码进行了直接拉伸,这破坏了window中的位置相对结构。他给出的解决方案很简单:每个window分别拉伸。
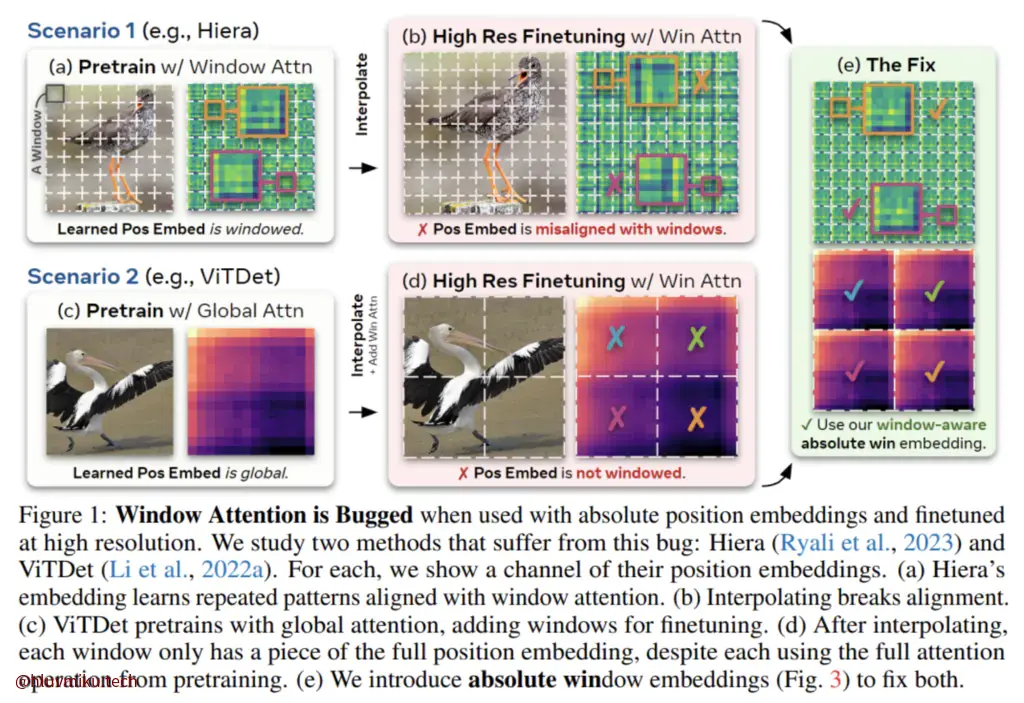
至此我们对Image Encoder部分有了基础的了解。
Memory Attention
我们再回顾一下SAM2的架构。与SAM不同,SAM2的feature在喂给Mask Decoder之前还过了一个Memory Attention,用以在模型内部propagate过去帧与标注帧的标注。
Each block performs self-attention, followed by cross-attention to memories of (prompted/unprompted) frames and object pointers (see below), stored in a memory bank (see below), followed by an MLP.
他的架构很简单,就是自注意力+交叉注意力接一个MLP。需要注意的是它对位置编码的设计。
In addition to sinusoidal absolute positional embeddings, we use 2d spatial Rotary Positional Embedding (RoPE) (Su et al., 2021; Heo et al., 2024) in self-attention and cross-attention layers. The object pointer tokens are excluded from RoPE as they do not have specific spatial correspondence.
实际上我对object pointers实现还是一知半解,这块等我读完Memory Bank代码再更新。
Prompt encoder and mask decoder
Prompt Encoder与SAM的实现一致。对于点,获取中心、padding后用一个learnable parameter加上位置编码作为最终embed,对于bbox,则取角点。点与框构成了sparse embedding。而mask则通过一个多层卷积将其卷成一个dense embedding。
Mask Decoder部分则与SAM的略有不同。
对比
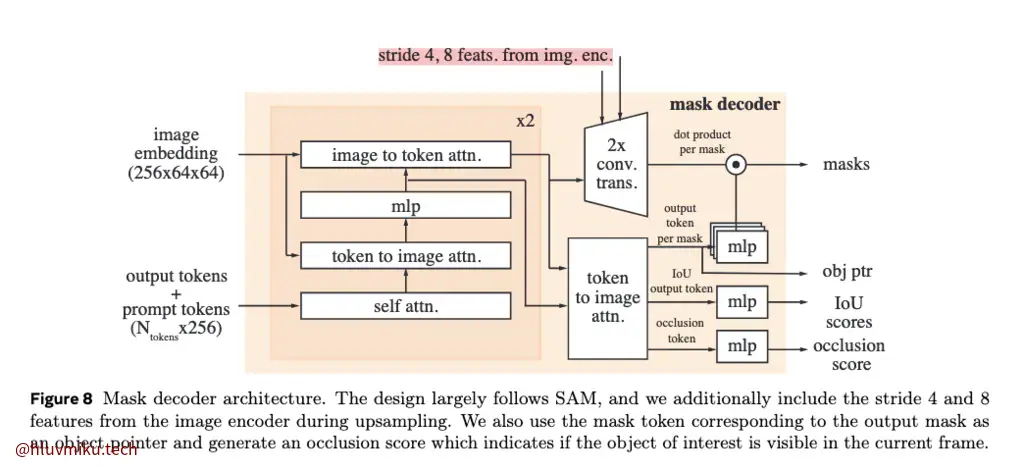
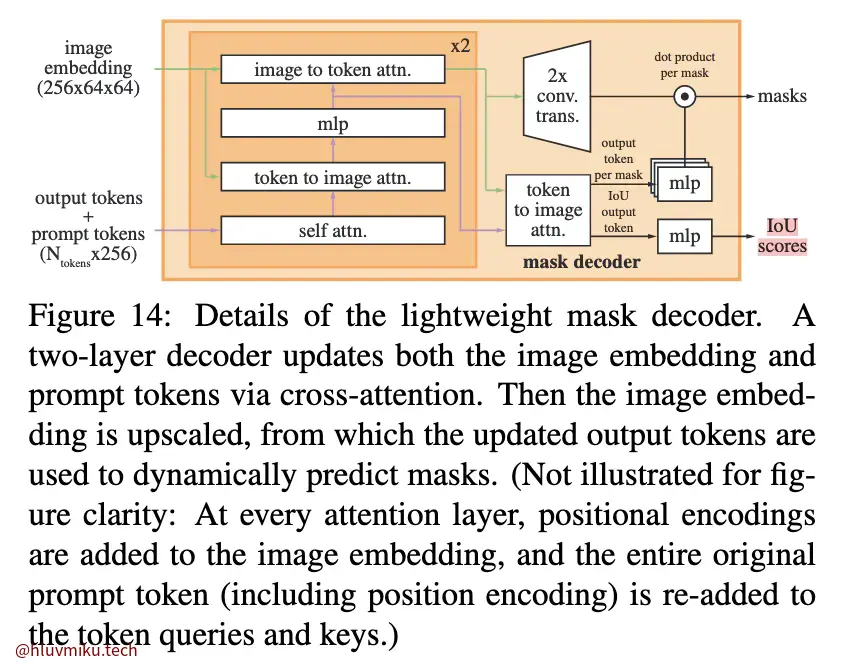
很明显的看到,SAM2的Decoder中多了一个预测该帧中是否有目标物体的分支。其他部分基本相同。因为“in the PVS task it is possible for no valid object to exist on some frames (e.g. due to occlusion).”
此外,还有一个不同之处在论文里没写,不过在图中画出来了:在上采用过程中,SAM2的卷积层额外接受了stride 4, 8 feats. from img. enc.,在SAM里并没有。
feat_s0, feat_s1 = high_resolution_features feat_s0 = feat_s0.repeat_interleave(point_batch_size, dim=0) feat_s1 = feat_s1.repeat_interleave(point_batch_size, dim=0) upscaled_embedding = self.upscale_conv1(image_embeddings) + feat_s1 upscaled_embedding = self.activation(self.upscale_layer_norm(upscaled_embedding)) upscaled_embedding = self.activation(self.upscale_conv2(upscaled_embedding) + feat_s0)这也是一个比较常规的操作,我想。不过让我想不明白的是为啥SAM里没加上它。
Memory Encoder & Memory Bank
This design allows the memory features to benefit from the strong representations produced by the image encoder (especially when we scale the image encoder to a larger size). Further, we project the memory features in our memory bank to a dimension of 64, and split the 256-dim object pointer into 4 tokens of 64-dim for cross-attention to the memory bank.
为了“记住”当前帧的结果,SAM2采用了一个简单的卷积模块将Mask与帧对应的Feature卷到mem_dim。而Memory Bank维护两个FIFO队列分别储存最近N帧和最近M标注帧。
In addition to the spatial memory**, we store a list of object pointers as lightweight vectors for high-level semantic information of the object to segment**, based on mask decoder output tokens of each frame. Our memory attention cross-attends to both spatial memory features and these object pointers.
另外,他还维护了一个存着Object Pointers的列表。这个Object Pointer我论文没咋看懂。代码实现里他是对最后的sam_output_token过了一个FeedForward作为最后储存的东西。我们直接看Memory Attention的代码好了,反正所有Memory都在那里用的:
# Step 1: Handle initial conditioning frames if is_initial_conditioning_frame: # For initial conditioning frames, no prior memory is used directly in this block. # If configured, directly add a learnable "no memory" embedding. # current_vision_features has shape (SeqLen, Batch, Channels) conditioned_feature_map_flat = current_vision_features + self.no_memory_embedding # Reshape to (Batch, Channels, Height, Width) conditioned_feature_map = conditioned_feature_map_flat.permute(1, 2, 0).view( batch_size, num_channels, height, width ) return conditioned_feature_map
# Step 2: Get memory frames and concatenate their features temporal_positions_and_previous_outputs = self._gather_memory_frame_outputs( inference_session, obj_idx, frame_idx, track_in_reverse_time )
memories_to_concatenate, memory_positional_embeddings_to_concatenate = self._build_memory_attention_inputs( temporal_positions_and_previous_outputs, device )
# Step 3: Get and process object pointers temporal_offsets, pointer_tokens, max_object_pointers_to_use = self._get_object_pointers( inference_session, obj_idx, frame_idx, num_total_frames, device, track_in_reverse_time, streaming )
num_object_pointer_tokens = 0 if pointer_tokens: object_pointers, object_pointers_pos_embed = self._process_object_pointers( temporal_offsets, pointer_tokens, max_object_pointers_to_use, batch_size, num_channels, device )
if object_pointers is not None: memories_to_concatenate.append(object_pointers) memory_positional_embeddings_to_concatenate.append(object_pointers_pos_embed) num_object_pointer_tokens = object_pointers.shape[0]
# Step 4: Concatenate all retrieved memories and their positional embeddings combined_memory = torch.cat(memories_to_concatenate, dim=0) combined_memory_positional_embeddings = torch.cat(memory_positional_embeddings_to_concatenate, dim=0)
# Step 5: Forward through the memory attention mechanism conditioned_feature_map_flat = self.memory_attention( current_vision_features=current_vision_features, current_vision_position_embeddings=current_vision_positional_embeddings, memory=combined_memory, memory_posision_embeddings=combined_memory_positional_embeddings, # Corrected typo from API num_object_pointer_tokens=num_object_pointer_tokens, )要理解这段代码,我认为核心在于“SAM2对于多目标任务,一次只关注一个目标,但是memroy缺却全存了起来”,为了区分不同目标,需要通过指定object pointer的方式实现。
终于,我们看完了整个SAM2的结构。
5. DATA
数据引擎构建也一直是SAM系列的亮点。SAM2采用了“渐进式”的SAM辅助标注。第一阶段纯SAM辅助人工标注,第二阶段SAM+SAM2混合辅助标注并迭代多轮,第三阶段纯SAM2标注并人工校对多轮。
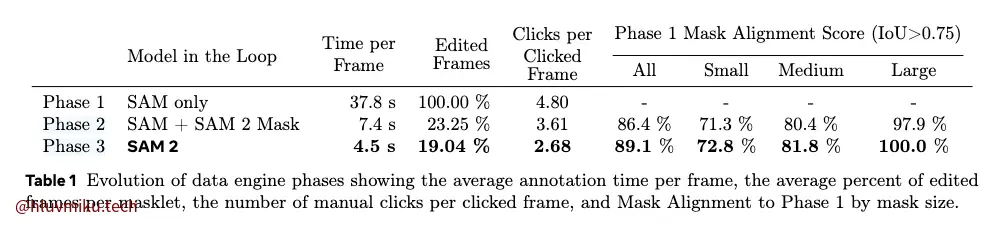
后几章就是zeroshot和semi-supervised的效果以及和sota比较,没啥要点。
总结
Memory Bank设计的非常精彩,传统的工程做法是在视频帧间通过算法实现一致性,而SAM2将其集成进了模型中。时序遥感图像序列的分割可以用类似方案吗?接下来该读读SAM3了。