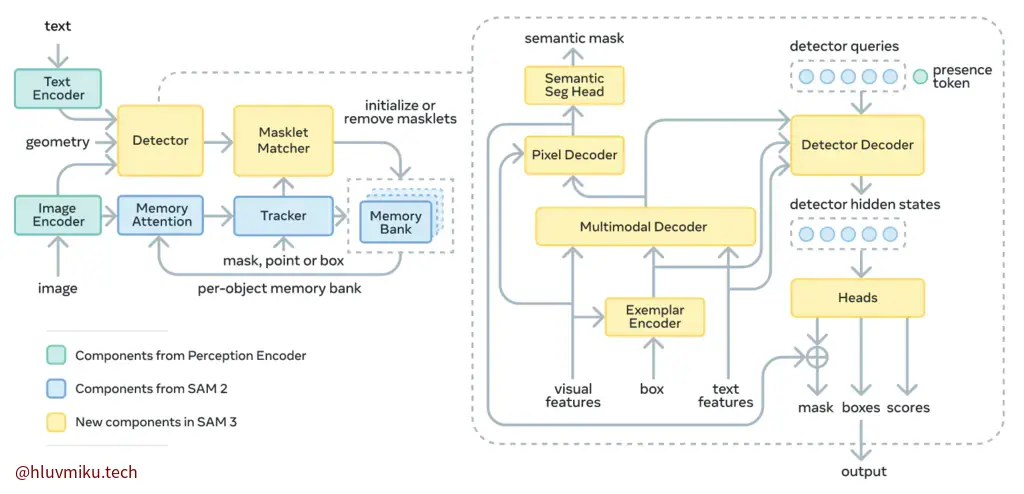
SAM3在SAM2的基础上,重新设计了整体结构,并且使其能进行PCS的task。整体架构在上面,有点复杂需要慢慢读,而且transformers库的实现也有SAM3,SAM3_tracker,SAM3_video,SAM3_trackr_vdieo四个版本,需要理解一下。我们先从核心概念看起。
Promptable Concept Segmentation (PCS)
我们比较一下SAM2与SAM3的task区别。
SAM2: PVS(Promptable Visual Segmentation)
Our PVS task allows providing prompts to the model on any frame of a video . Prompts can be positive/negative clicks, boxes, or masks , either to define an object to segment or to refine a model-predicted one. To provide an interactive experience, upon receiving a prompt on a specific frame, the model should immediately respond with a valid segmentation mask of the object on this frame . After receiving initial prompts (either on the same frame or different frames), the model should propagate these prompts to obtain the masklet of the object across the entire video , localizing the segmentation mask of the target on every video frame. Additional prompts can be provided to the model on any frame to refine the segment throughout the video (example in Fig. 2).
SAM3: PCS(Promptable Concept Segmentation)
We define the Promptable Concept Segmentation task as follows: given an image or short video (≤30 secs), detect, segment and track all instances of a visual concept specified by a short text phrase, image exemplars, or a combination of both. We restrict concepts to those defined by simple noun phrases (NPs) consisting of a noun and optional modifiers. Noun-phrase prompts (when provided) are global to all frames of the image/video, while image exemplars can be provided on individual frames as positive or negative bounding boxes to iteratively refine the target masks (see Fig. 3).
简要来说,SAM3期望达到通过简单名词短语和少量图像标注对所有目标进行标注、追踪。关于视频与目标追踪,SAM2将其视为一个整体——通过MemoryBank进行统一储存与 propagate ,然后通过object id与匹配算法进行追踪,而SAM3则将其拆开了,追踪是追踪,匹配是匹配,我们在Model里会详细研究。
Model & Appendix C. Model Details
我读SAM3主要是为了学习它的模型设计思想与用到的技术,所以这块我会读的比较细致。
Image and Text Encoders
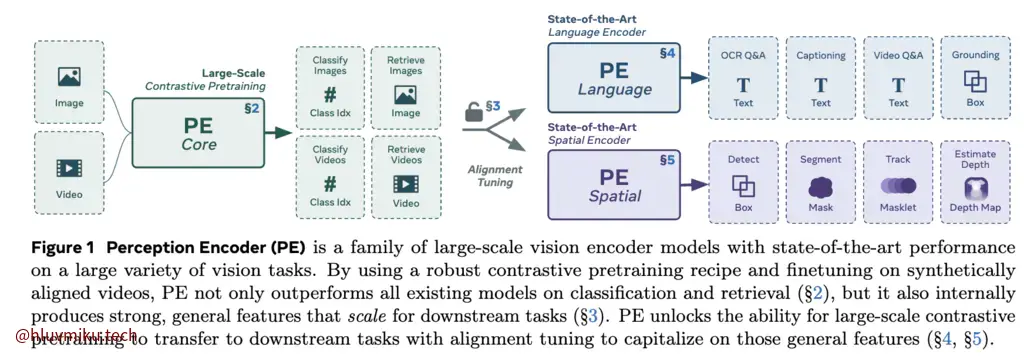
要实现Concept Segmentation,核心的就是建立Text与Image在Concept上的匹配关系,在这里,SAM3采用了META自家的Perception Encoder,与CLIP类似,它也是基于constrastive vision language training的。在PE中,作者提出了一个有趣的发现:
Surprisingly, after scaling our carefully tuned image pretraining recipe and refining with our robust video data engine, we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the intermediate layers of the network. To draw them out, we introduce two alignment methods: language alignment for multimodal language modeling, and spatial alignment for dense prediction.
为此,他们在类似CLIP的训练过程之后,对Language Encoder与Spatial Encoder独立进行了Alignment。
事实上,PE_lang与PE_Spatial独立进行Alignment后他们vision-language pair的准确性如何我好像没在论文看到,可能我草草看的太快了,需要再读读。
Detector Architecture
这里非常复杂,需要逐个拆解。我把它拆成了3块。简单来说,SAM3 Detector里集成了一个Prompt Encoder(Geometry Encoder),一个完整的DETR与一个类似SAM1/2 MaskDecoder的Mask Decoder。
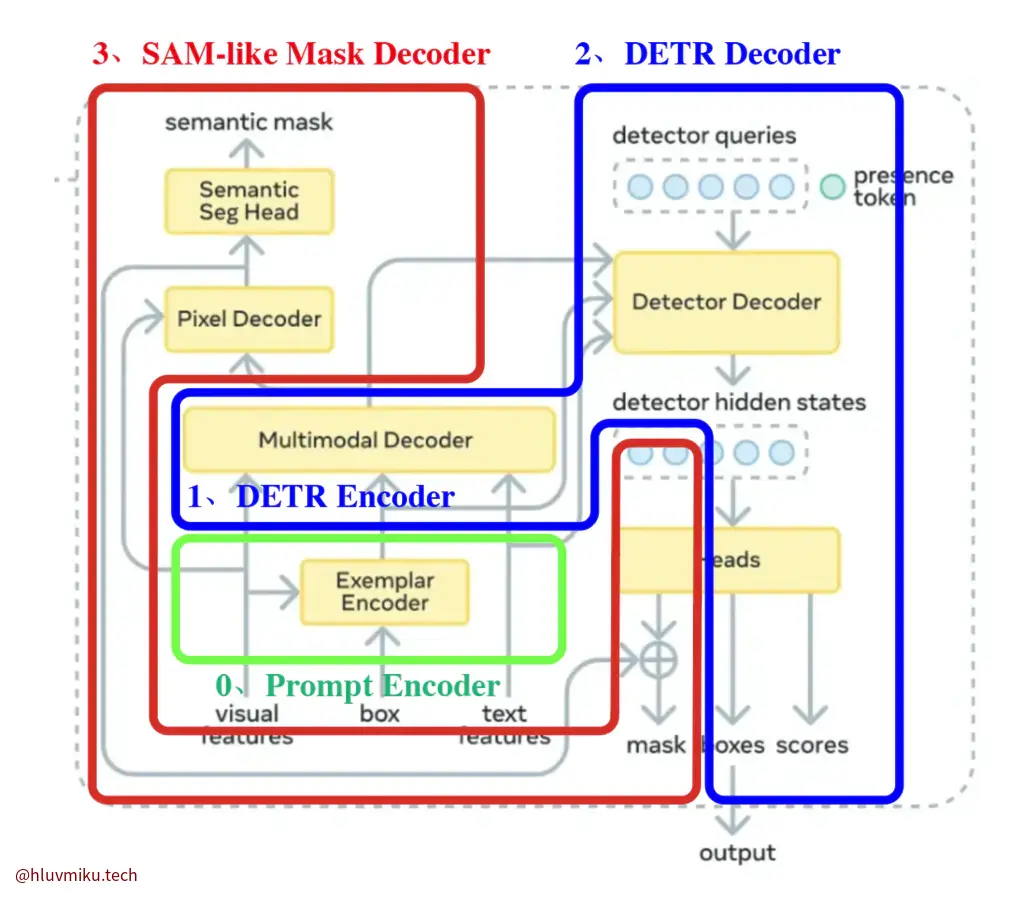
0. Prompt Encoder(Geometry Encoder)
所有Geometry相关的feature都会与visual features一起喂给ExemplarEncoder:
geometry_outputs = self.geometry_encoder( box_embeddings=box_embeddings, box_mask=box_mask, box_labels=box_labels, img_feats=fpn_hidden_states, img_pos_embeds=fpn_position_encoding, )1. DETR Encoder
这之后,再把geometry_outputs、fpn_hidden_states、text_feature全塞到一起:
encoder_outputs = self.detr_encoder( vision_features=[fpn_hidden_states[-1]], text_features=combined_prompt_features, vision_pos_embeds=[fpn_position_encoding[-1]], text_mask=combined_prompt_mask, **kwargs, )这里的detr_encoder看起来应该就是paper里的”Multimodal Decoder”。
2. DETR Decoder
在decoder中,文章引入了一个额外的presence token,将“目标是否存在”从全局Token里解耦了。
However, forcing proposal queries to understand the global context can be counterproductive, as it conflicts with the inherently local nature of the localization objective. We decouple the recognition and localization steps by introducing a learned global presence token.
3. Mask Decoder
Mask Decoder中有一个Pixel Decoder和一个Semantic Seg Head,在具体实现里,这个MaskDecoder就是一个简单的FPN,而Semantic Seg Head则是一层卷积层。需要注意的是Mask Decoder接收DETR Decoder的hidden state作为ObjectMask的Query,经过MLP后与pixel feature做点积得到最终的mask,类似MaskFormer。
pixel_embed = self._embed_pixels( backbone_features=backbone_features, encoder_hidden_states=encoder_hidden_states, )
# Predict instance masks via dot product between query embeddings and pixel embeddings instance_embeds = self.instance_projection(pixel_embed) mask_embeddings = self.mask_embedder(decoder_queries) pred_masks = torch.einsum("bqc,bchw->bqhw", mask_embeddings, instance_embeds)训练方式
During training, we adopt dual supervision from DAC-DETR (Hu et al., 2023), and the Align loss (Cai et al., 2024).
在监督方面,SAM3采用了dual supervision与Align loss,我们逐个来看。Dual Supervision是DAC-DETR提出的。DAC-DETR注意到Self-Attn与Cross-Attn的作用相反——一个分离各个query,一个拉近各query。
• Cross-attention layers tend to gather multiple queries around the same object. Given an alreadytrained Deformable DETR [45], we remove all the self-attention layers in its decoder. This removal compromises DETR to duplicate detections. As illustrated in Fig. 1 (b), multiple queries locate a same object (“bear”) with relatively large Intersection-over-Union (IoU). Compared with their initial states (before the decoder) in Fig. 1 (a), they become closer towards each other, regarding both their position (1st row) and feature distance (2nd row). • Self-attention layers disperse these queries from each other. In Fig. 1 (c), we restore the original deformable DETR. Correspondingly, the queries are dispersed from each other regarding both position (1st row) and feature distance (2nd row). Due to this dispersion, most queries become farther to their original center point, except that a single query (with the highest classification score) approaches even closer. This phenomenon explains how DETR makes non-duplicate detection, and is consistent with the consensus [23, 3, 41, 25], i.e., self-attention layers play a critical role in removing duplicates.
于是它设计了一个双路结构,一路遵守原始的DETR训练逻辑,另一路训练时跳过Self-Attn,Eval时忽略:

而Align Loss是在Align-DETR中提出的。文章认为传统的训练方式存在着两个misalignment: classification-regression misalignment and cross-layer target misalignment。
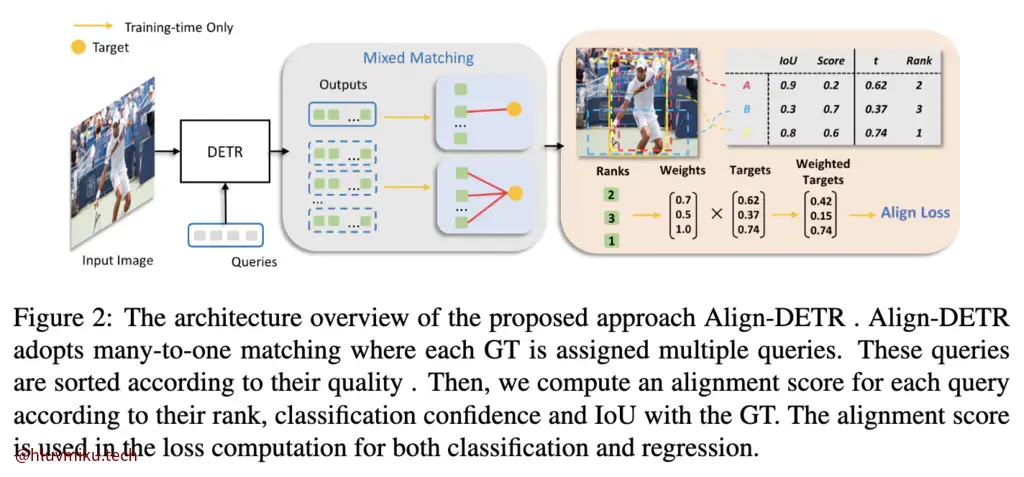
所以他设计了一个比较能自适应的Align策略:
反正就是把一个hard的target转换成了soft的label。(这篇没细看)
The mask head is adapted from MaskFormer (Cheng et al., 2021).
他的mask head是从MaskFormer里来的,就是这个非常经典的结构:
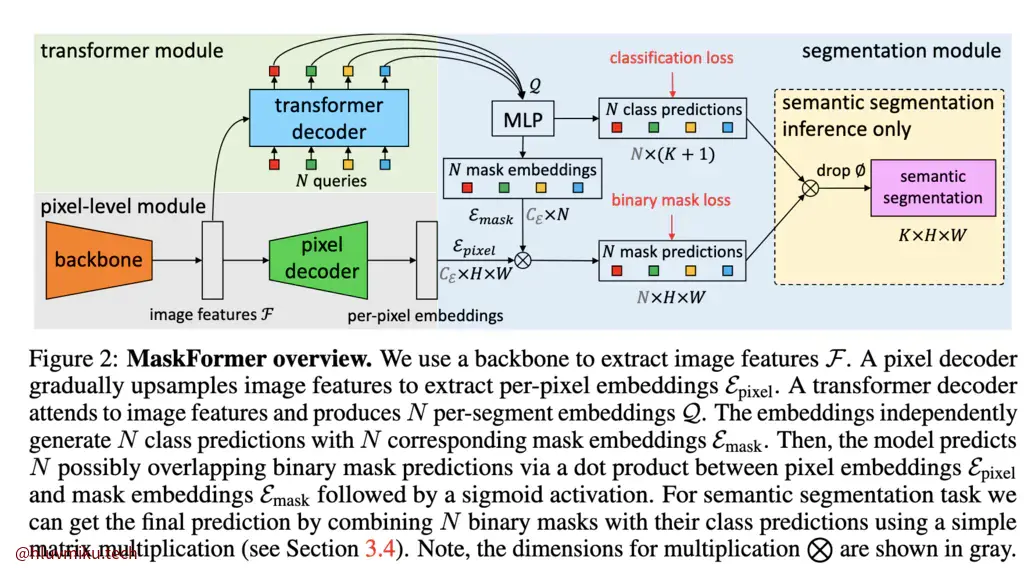
其他也还有一些Mask匹配相关内容,我感觉过于工程就不想写了,没啥亮点。
To reduce spurious and duplicate masklets, we delay the output of the model slightly. Specifically, the output at frame τ is shown only after observing frame τ + T .
这里倒是有点意思。
总结
数据引擎、消融实验啥的也都中规中矩,没特别多亮眼的地方。总之我感觉SAM3不如SAM2惊艳,更像是工程问题。在读之前我期待能看到SAM3在Concept to “Prompt”或者类似grounding之类的工作上能有突破,结果却是纯拼接。总之就这样吧,之后回去看DINO了。