概览
该工作提出了一种端到端的多尺度Siamese框架,其架构设计体现了”强先验+精细推理”的思想。主要包含四个关键模块:
- DINOv3预训练编码器:语义注入
- 密集特征融合模块(DFFM):跨层级信息聚合
- 空间-光谱差分Transformer解码器(S2DT):核心创新
- 可学习形态学模块(LMM):边界精细化
DINOv3预训练编码器
简要地来说,它把MobileNet的后4层feature作为Multi-Scale Features,将它与DINOv3的第 5、11、17、 23的patch进行Project后concat起来作为最后的feature。我感觉很奇怪,纯 ViT 本来只有一个 patch grid,怎么能用它来作为所谓的“Multi-Scale Features”呢?这么concat起来真的合乎逻辑吗?我问了GPT,它回答说:
对 ViT 做 “伪多尺度” 本来就是主流 trick
纯 ViT 本来只有一个 patch grid(这里是 32×32),业界常用的方法有:
- 选多个层(深度)作为不同“语义层级”, 用插值/池化/卷积构成多尺度特征,再接 FPN / U-Net decoder。
- 比如一些 ViT segmentation / detection 论文、DPT、某些 SegFormer-like 结构也会类似地对 ViT 特征做上/下采样,构建 “FPN-like” 金字塔,然后和 CNN 套路保持一致。
我还是对这个做法保持怀疑🤨,但因为我目前不涉及这方面内容,暂且搁置,日后如果遇到再探讨。
密集特征融合模块(DFFM)
为了更好的融合特征,他使用了深度可分离卷机(depthwise–separable convolution)和 CBAM Attention。为啥使用深度可分离卷机呢?他也没说。可能就是为了加速训练吧?简单来说,它用了“Depthwise Convolution”对每个维度独立卷机,接着使用“Pointwise Convolution”对跨维度的同一poison卷机,比原来的同时对所有维度同一位置卷机轻量化了一点。而CBAM Attention则比较有趣:
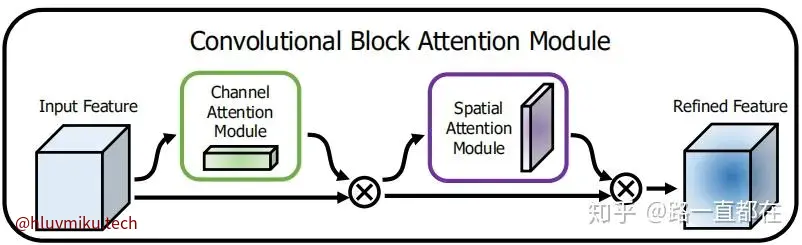
进行完这些操作就得到了最终的Feature。
空间-光谱差分Transformer解码器(S2DT)
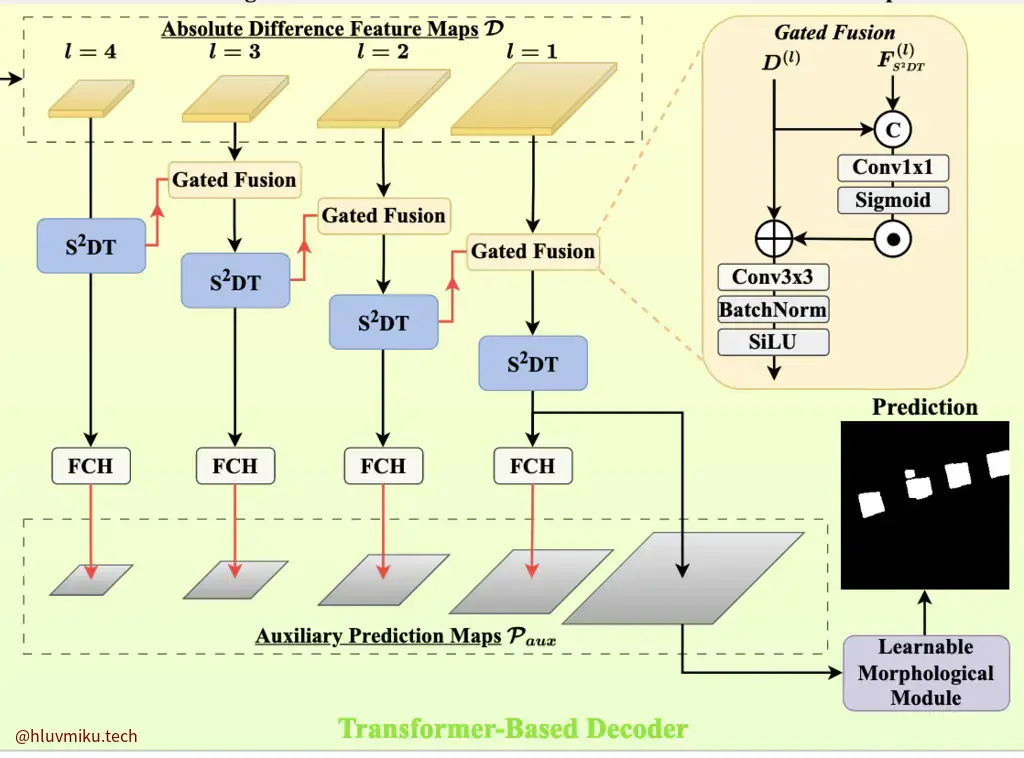
用不同时间的两个feature相减就得到了最后需要使用的feature。拿到feature后就该完成自己的task了: Remote sensing change detection 。这块我不懂,不过他用到了Differential transformer,这还是蛮有趣的。它是在LLM里用来“降噪”的transformer。他说这个差分注意力机制
well suited here for filtering illumination-induced or misregistration artifacts and other irrelevant responses.
其他地方看着挺常规的。
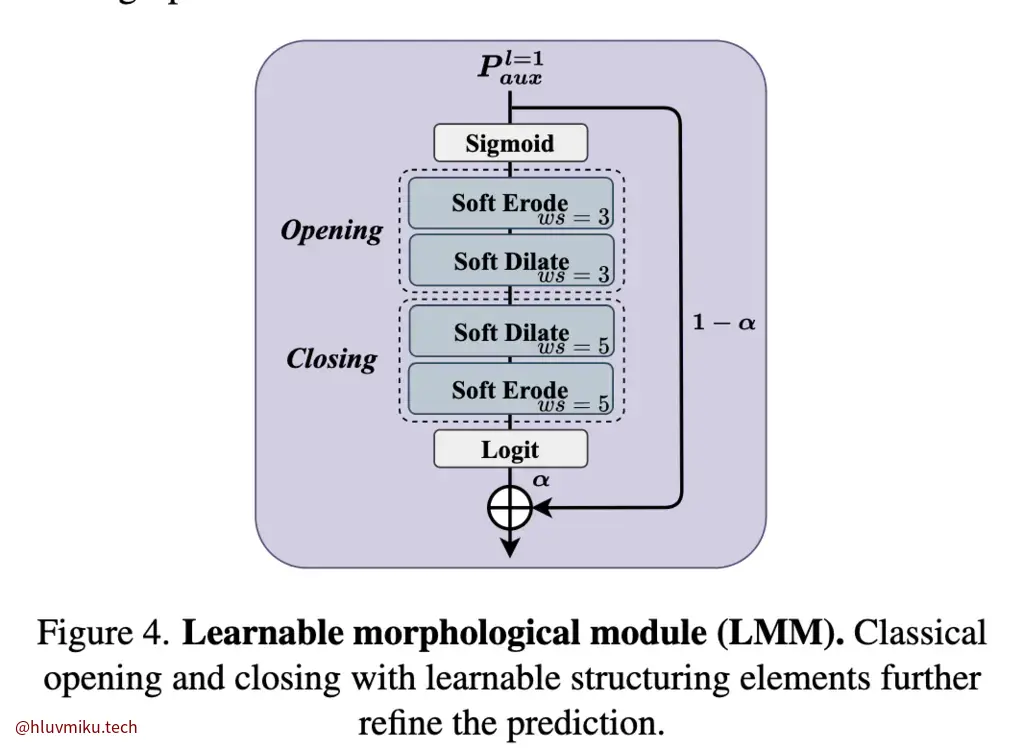
可学习形态学模块(LMM)
最后的这个LMM就是在试着优化传统用来平滑、侵蚀、扩张最终生成mask的算法。原来一般都是拿3*3的矩阵直接卷机,这里它引入了可学习变量怎么算了一下。
消融实验
本着对他设计模块效果的质疑,我直接略过了效果,直接看他的消融实验:
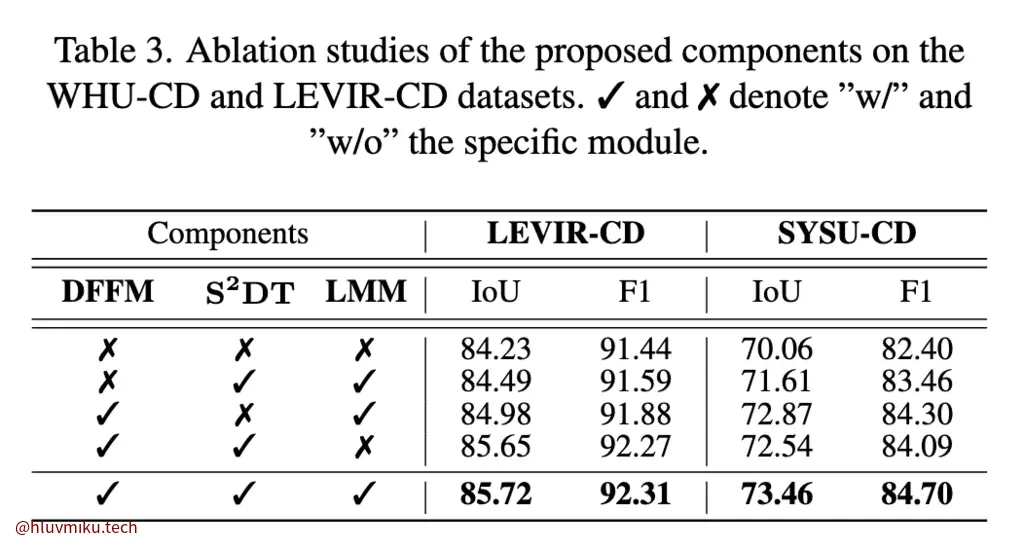
三个模块全去掉,只使用DINO feature在LEVIR-CD上效果感觉已经很不错了,其他的感觉有点像个添头,但毕竟也提升了两三个点,其实也挺多的了。
最后附上效果:
